Quickstart for Managed Postgres
ClickHouse Managed Postgres is enterprise-grade Postgres backed by NVMe storage, delivering up to 10x faster performance for disk-bound workloads compared to network-attached storage like EBS. This quickstart is divided into two parts:
- Part 1: Get started with NVMe Postgres and experience its performance
- Part 2: Unlock real-time analytics by integrating with ClickHouse
Managed Postgres is currently available on AWS in several regions and is free during private preview.
In this quickstart, you will:
- Create a Managed Postgres instance with NVMe-powered performance
- Load 1 million sample events and see NVMe speed in action
- Run queries and experience low-latency performance
- Replicate data to ClickHouse for real-time analytics
- Query ClickHouse directly from Postgres using
pg_clickhouse
Part 1: Get Started with NVMe Postgres
Create a database
To create a new Managed Postgres service, click on the New service button in the service list of the Cloud Console. You should then be able to select Postgres as the database type.
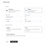
Enter a name for your database instance and click on Create service. You will be taken to the overview page.
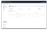
Your Managed Postgres instance will be provisioned and ready for use in 3-5 minutes.
Connect to your database
In the sidebar on the left, you will see a Connect button. Click on it to view your connection details and connection strings in multiple formats.
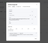
Copy the psql connection string and connect to your database. You can also use any Postgres-compatible client such as DBeaver, or any application library.
Experience NVMe performance
Let's see NVMe-powered performance in action. First, enable timing in psql to measure query execution:
Create two sample tables for events and users:
Now, insert 1 million events and watch the NVMe speed:
1 million rows with JSONB data inserted in under 4 seconds. On traditional cloud databases using network-attached storage like EBS, this same operation typically takes 2-3x longer due to network round-trip latency and IOPS throttling. NVMe storage eliminates these bottlenecks by keeping storage physically attached to the compute.
Performance varies based on instance size, current load, and data characteristics.
Insert 1,000 users:
Run queries on your data
Now let's run some queries to see how fast Postgres responds with NVMe storage.
Aggregate 1 million events by type:
Query with JSONB filtering and date range:
Join events with users:
At this point, you have a fully functional, high-performance Postgres database ready for your transactional workloads.
Continue to Part 2 to see how native ClickHouse integration can supercharge your analytics.
Part 2: Add Real-Time Analytics with ClickHouse
While Postgres excels at transactional workloads (OLTP), ClickHouse is purpose-built for analytical queries (OLAP) on large datasets. By integrating the two, you get the best of both worlds:
- Postgres for your application's transactional data (inserts, updates, point lookups)
- ClickHouse for sub-second analytics on billions of rows
This section shows you how to replicate your Postgres data to ClickHouse and query it seamlessly.
Setup ClickHouse integration
Now that we have tables and data in Postgres, let's replicate the tables to ClickHouse for analytics. We start by clicking on ClickHouse integration in the sidebar. Then you can click on Replicate data in ClickHouse.

In the form that follows, you can enter a name for your integration and select an existing ClickHouse instance to replicate to. If you don't have a ClickHouse instance yet, you can create one directly from this form.
Make sure the ClickHouse service you select is Running before proceeding.

Click on Next, to be taken to the table picker. Here all you need to do is:
- Select a ClickHouse database to replicate to.
- Expand the public schema and select the users and events table we created earlier.
- Click on Replicate data to ClickHouse.

The replication process will start, and you will be taken to the integration overview page. Being the first integration, it can take 2-3 minutes to setup the initial infrastructure. In the meantime let's check out the new pg_clickhouse extension.
Query ClickHouse from Postgres
The pg_clickhouse extension lets you query ClickHouse data directly from Postgres using standard SQL. This means your application can use Postgres as a unified query layer for both transactional and analytical data. See the full documentation for details.
Enable the extension:
Then, create a foreign server connection to ClickHouse. Use the http driver with port 8443 for secure connections:
Replace <clickhouse_cloud_host> with your ClickHouse hostname and <database_name> with the database you selected during replication setup. You can find the hostname in your ClickHouse service by clicking Connect in the sidebar.
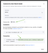
Now, we map the Postgres user to the ClickHouse service's credentials:
Now import the ClickHouse tables into a Postgres schema:
Replace <database_name> with the same database name you used when creating the server.
You can now see all the ClickHouse tables in your Postgres client:
See your analytics in action
Let's check back on the integration page. You should see that the initial replication is complete. Click on the integration name to view details.

Click on the service name to open the ClickHouse console and see your replicated tables.

Compare Postgres vs ClickHouse performance
Now let's run some analytical queries and compare performance between Postgres and ClickHouse. Note that replicated tables use the naming convention public_<table_name>.
Query 1: Top users by activity
This query finds the most active users with multiple aggregations:
Query 2: User engagement by country and platform
This query joins events with users and computes engagement metrics:
Performance comparison:
| Query | Postgres (NVMe) | ClickHouse (via pg_clickhouse) | Speedup |
|---|---|---|---|
| Top users (5 aggregations) | 555 ms | 164 ms | 3.4x |
| User engagement (JOIN + aggregations) | 1,246 ms | 170 ms | 7.3x |
Even on this 1M row dataset, ClickHouse delivers 3-7x faster performance on complex analytical queries with JOINs and multiple aggregations. The difference becomes even more dramatic at larger scales (100M+ rows), where ClickHouse's columnar storage and vectorized execution can deliver 10-100x speedups.
Query times vary based on instance size, network latency between services, data characteristics, and current load.
Cleanup
To delete the resources created in this quickstart:
- First, delete the ClickPipe integration from the ClickHouse service
- Then, delete the Managed Postgres instance from the Cloud Console
